Page oriented storage
B-Tree
The most widely used indexing structure. Instead of having the log indexing on variable size segments and always write a
segment sequentially. B tree uses fixed-size pages, and read or write one page at a time. The database engine primarily
builds B tree structures(Disk-Based B-Trees) on disk, the leaf contains the ref(disk address) to the actual data.
In-Memory B-Trees (Performance-Driven Scenarios), Certain database systems, primarily In-Memory Databases (IMDBs), keep the entire B-tree index in memory.
Log indexing
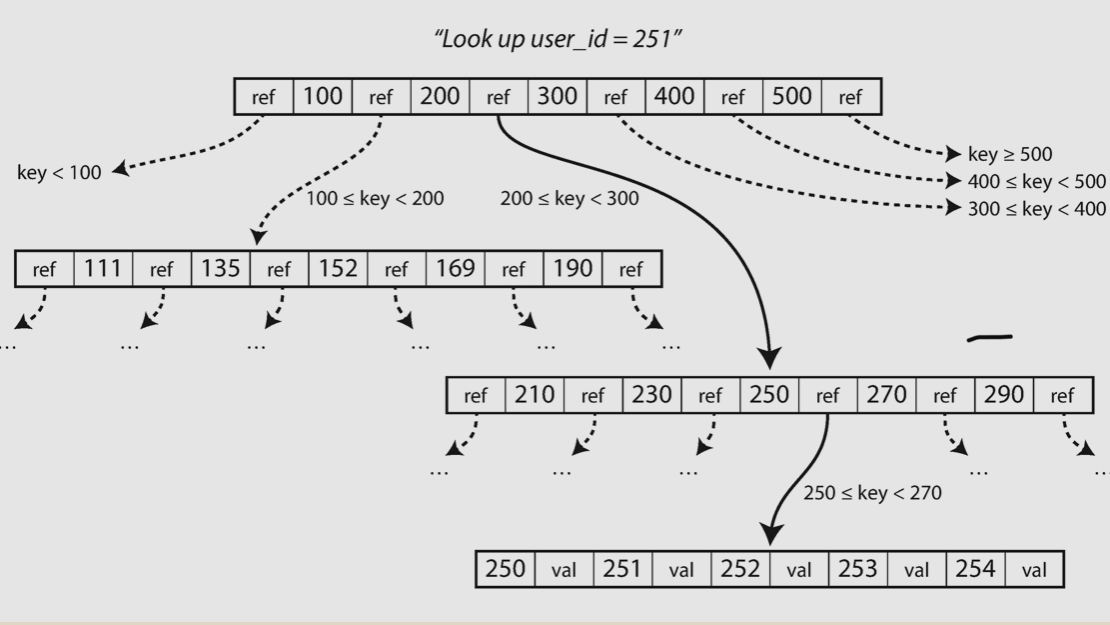
B tree indexing
On read
- Starting from the root of B tree
- Find the sub page between the boundaries of two keys until hit the leaf
- The leaf has the ref to actual data
On write
- If updating the existing data
- Starting from the root and find the leaf
- Update the data or page directly
- If inserting a new data
- Starting from the root and find the leaf
- If there is space, then just insert the key and value holds the ref to actual data
- If there is no space, then split the leaf into two, then insert the data
- Starting from the root and find the leaf
Crash recovery
The B tree is in memory, if system crashes we need to rebuild the B tree. This could be done from write-ahead-log.
Concurrency
Latches (lightweight locks) is used to protect the page from modified by concurrent thread/processes.
Improvements
- Using locks to protect the critical data being modified by multiple threads/processes could be improved.
- A modifed page could be written to a different location
- A new version of its parent page is created and point to the new location
- Key could be stored as abbreviation to save spaces
- Try to lay out the B-Tree, so that nearby keys could be stored nearby on disk
- Add sibling pointers between different leaves page to improve lookup without jumping back to parent page