Design instant messaging system
This is the notes for designing a facebook messager, Tencent wechat, Whatsapp, Slack, Alibaba Dingding like instant messaging system.
User stories
- As a user, I would like to send text/picture/video messages to another friend. (1:1 messaging)
- As a user, I would like to send text/picture/video messages to a group of friends. (Group messaging)
- As a user, I would like to use different devices to send/recieve messages, e.g. mobile app client and laptop app client. (NOT simultaneously)
- As a user, I would like the data to be persistent, so that different devices could load the full history of the message. (Message roaming)
Out of scope for future research
- Rate limiting
- Search
- Monitoring and Logging
- Voice or Video calls
Assumptions
- 75m DAU, 7KB/text message, 30 msgs/day
- Assume user would send message to
onlineuser most of the time
Data model
Client
// POST /api/v1/rtm.send
{
"sourceID": "xxxxxx", // message producer
"targetID": "xxxxxx", // clientID or groupID of the message consumer
"text": "hello"
}
{
"sourceID": "xxxxxx", // message producer
"targetID": "xxxxxx", // clientID or groupID of the message consumer
"encodedMedia": "4jsxied==" // binary encoded media data
}
// GET /api/v1/rtm.receive
{
"sourceID": "xxxxxx", // message consumer
"targetID": "xxxxxx", // message producer
"lastPos": "jD9ace6==" // the hash indicates the last read from message queue
}
Message Server
type Message struct {
// channelID:timestamp to make it global unique, channelID could be mapped from sourceID and targetID if 1:1
// messaging, or channelID could be the targetID if group messaging
sequenceID string
text string // text content of the message
mediaURL string // the URL
}
Message processing backend
type MessageQueue struct {
messages []Message
}
// In memory buffer to handle the incoming messages
// wait worker to process the message
type MessageBuffer struct {
MessageQueue
}
// A collection of MessageQueue
type MessageQueues struct {
messageQueues []MessageQueue
}
MessageQueue:
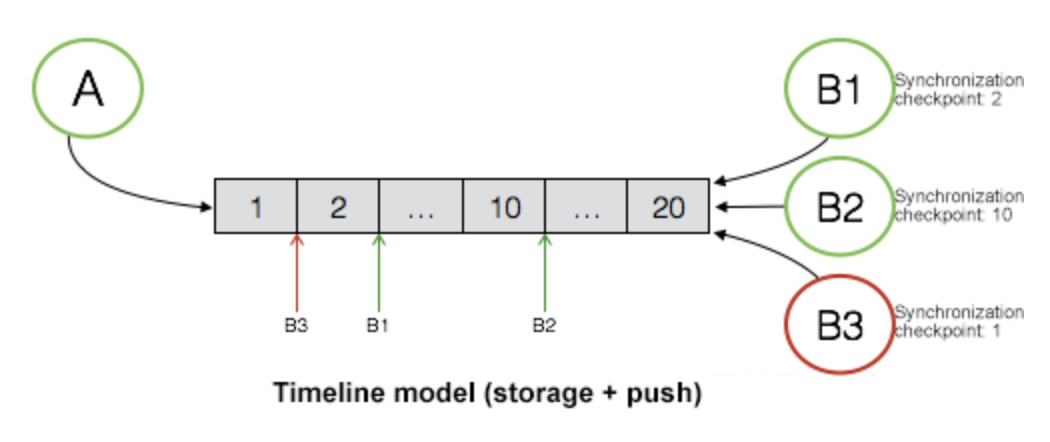
- Each message has an incremental ID,
sequenceID. - New messages are appended only, so that the messages in the queue is sorted based on the delivery order.
- Allow read from a position.
Architecure
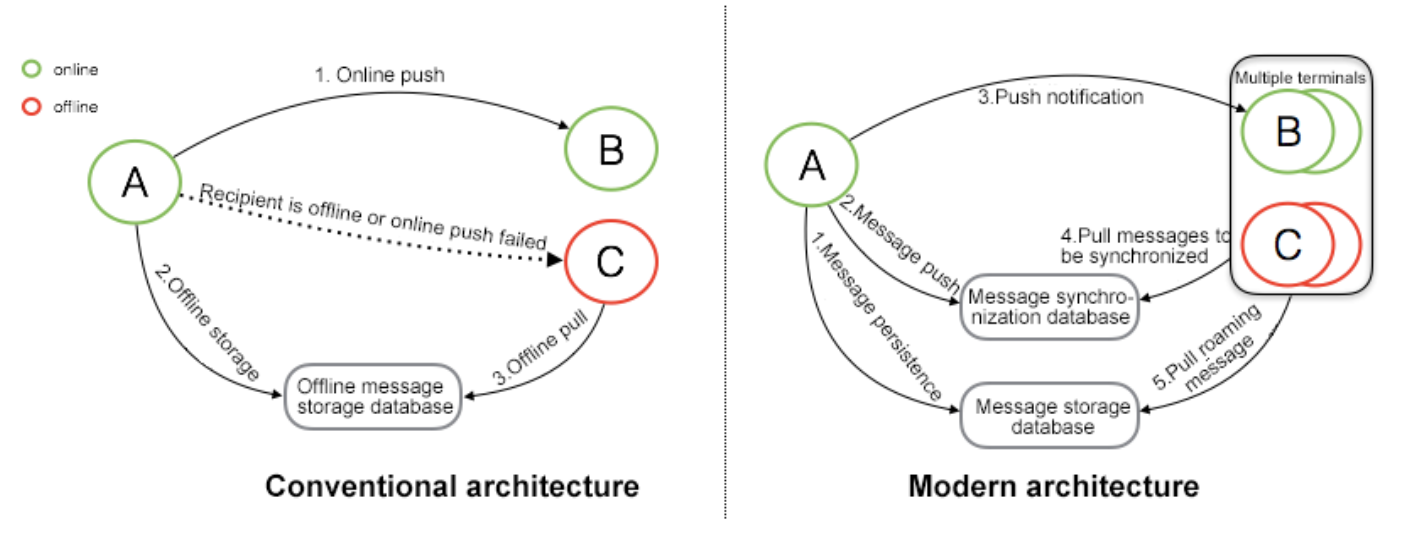
Conventional architecture
- If target is online, then messages are directly synced without storing in DB
- If target is offline, the messages will be stored in
offlineDB - When target is back online, it could read from the
offlineDB
Analysis:
- This architecture seems nicely fit Snapchat use cases where message is sent and deleted.
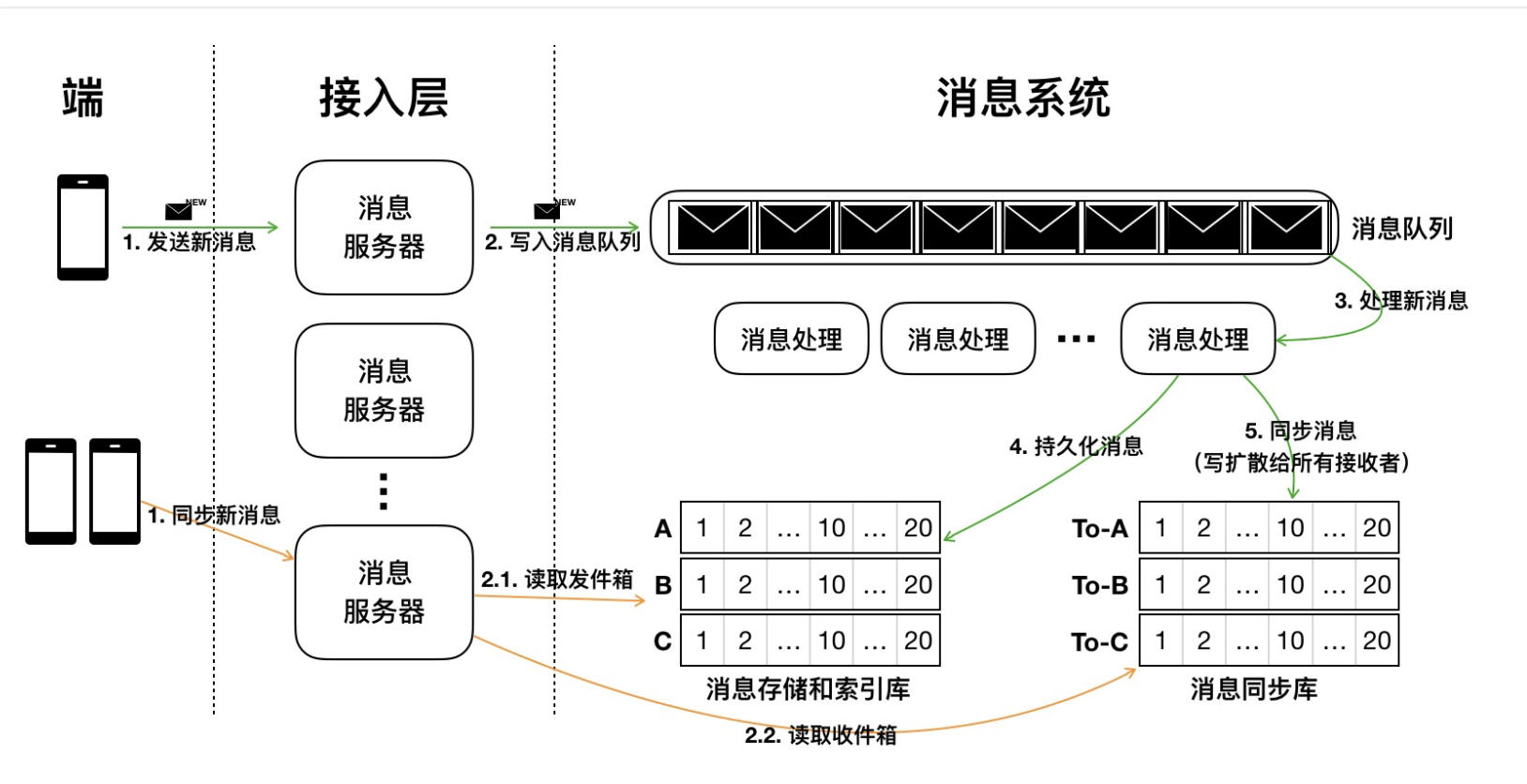
Modern architecture
- Messages are stored in
MessagePersistentStorefirst - Once messages are stored successfully, they will be pushed to
MessageSyncStore - A notification will be sent to target which indicates there are new messages
- Target pull messages from
MessageSyncStore
Analysis:
- When target recieves the messages, they are guaranteed to be persistent already
- Multiple target devices could pull messages from the
MessageSyncStoreat the same time MessagePersistentStoreallows messages could be persistent and message roaming
How messages are synced
Pull model
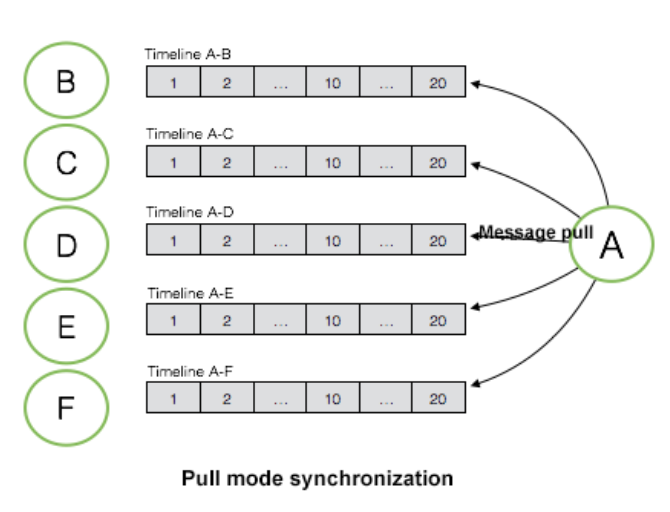
- Each individule sender maintains an message queue (overall it is a
MessageQueues), every time when a sender wants to send data no matter target is online or offline, it sends to its own message queue. E.g.Bhas a session withA,Bsends data into theA-Bqueue. - Every time when receiver wants to read messages, it
pulls from each message queue.
For example, I was chatting with 10 of my friends, there will be 10 message queues between my friends and I. Each time I open the app, it loops on all message queues to pull the messages.
The cons of this approach are:
- On read-heavy case, the
loop on all queuesis inefficient. Because not all queues have new messages.
Push model
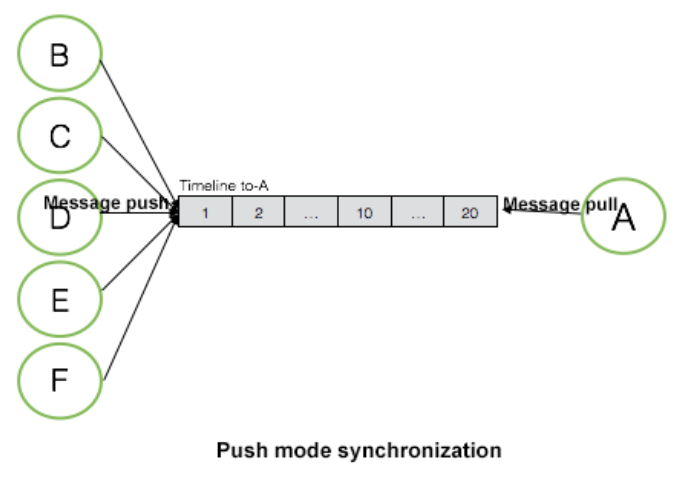
- The receiver maintains a big message queue, all senders send new messages to this queue for message sync. It combines all messages from all senders.
- When receiver wants to read, it just read from the queue.
The cons of this approach are:
- If user has several big groups with 1000 members, there could be lots of write(write heavy). Using this model will cause high latency on 1:1 messaging, because there could be tons of group messages in the queue.
Conclusion
Most of the IM systems are using push model for 1:1 messaging and pull model for group messaging.
How messages are persisted
What are the requirements
- Heavy on read (Reading messages are much more than writing)
- We want each nodes to could split the reads
- Concurrent writes (Huge amount of writes, and network delay could result in concurrent writes to DB)
- We need the DB can handle the concurrent write well
- We want data on all nodes are consistent
Options
Debates between Leader based or Leaderless. Amazon Chime uses DynamoDB which is leader based. And Slack uses MySQL
cluster which is active-active with strong consistency. Alibaba Dingding uses Table Store which is also a leader based
system. Using Cassandra(leaderless) should also be fine which has good performance but needs some mechanism to
coordinate the message consistency on all nodes and the ordering (which could be easily handled in leader based).
What other companies are using
- Dynamo DB (Amazon Chime)
- Table Store (Alibaba Dingding)
- MySQL cluster + Vitess (Slack)
Overall architecture
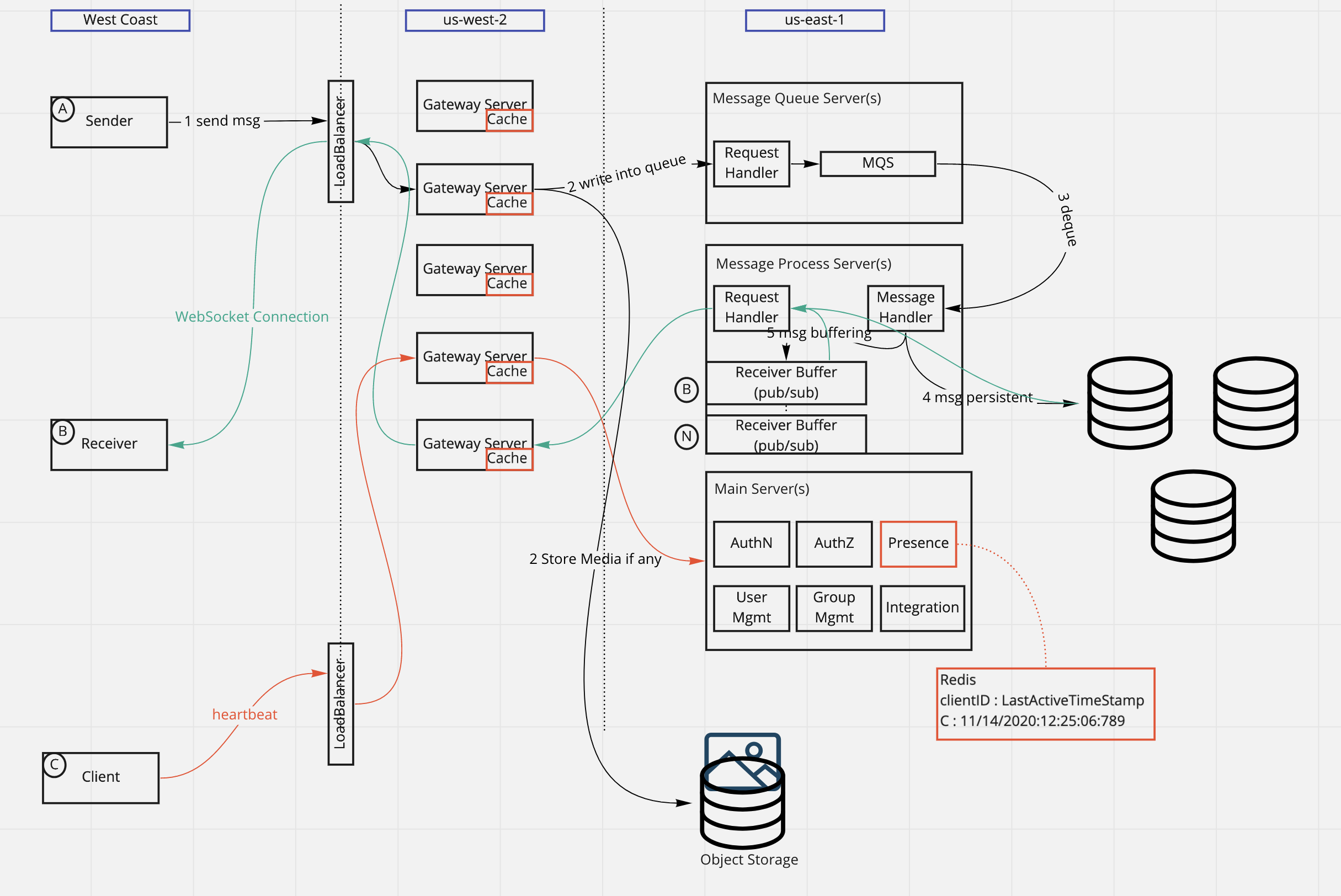
Dingding’s architecture
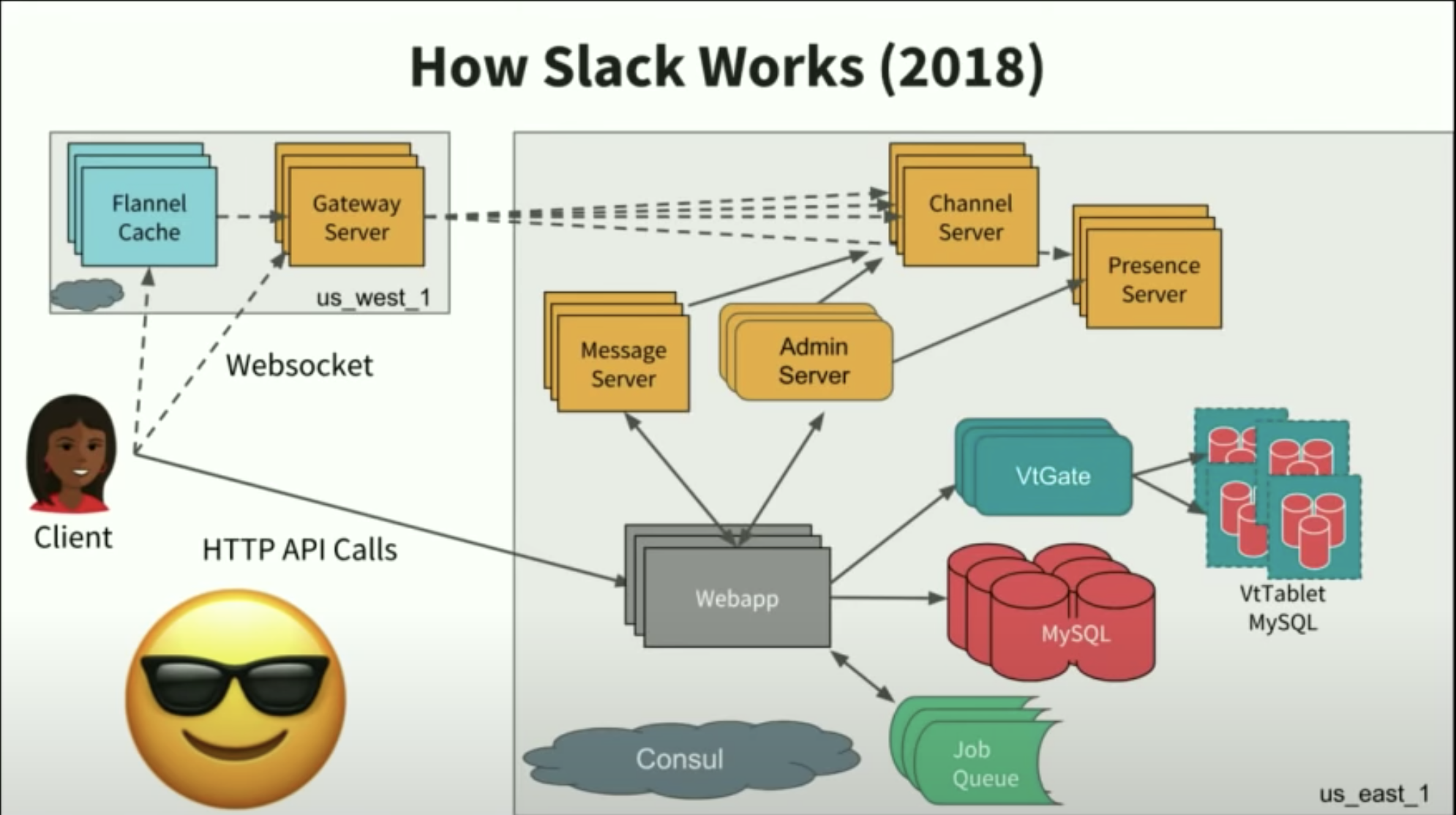
Slack’s architecture
Questions
- what happens if we could add msg to
msg sync queuebut not inmsg persistent queue?- network partition makes the data persistent process delays. we might want to have a on-disk
msg sync queuewith a relatively larger size to temporarily persist the data on local disk, then the data persistent process could periodically back up the snapshot of the local on-diskmsg sync queue. - or make the in-memory
mgs sync queuelarger ?
- network partition makes the data persistent process delays. we might want to have a on-disk
- A new group member is added to the group, do we allow him/her to see the full history ?
- How to deal with high peak of re-connection ? Flannel(Slack)
- Why we need
Gateway serverlayer ?- Close to end users
- Improve performance by caching
Miscellaneous
- Slack is using:
Redisas the job queueMemecachedfor cachingVitess+MySQL Cluster(master-master strong consistent model) for data persistentSolrfor search- Team partitioning (Orgnization)
- Easy to scale to lots of teams
- isolate failures and performance issues