Twine: A Unified Cluster Management System for Shared Infrastructure
What is Twine
- A cluster management system helps to convert dedicated machines cross data centers/regions into a large scale shared infrastructure.
- Single control plane
- LCM of millions of machines.
- LCM of containerized applications across clusters.
Why does Facebook need Twine
Limitations from existing system(K8S)
- Focus on isolated single cluster. (TODO: K8S Cluster Federation and Multi cluster service)
- Does not consult an application when performing the LCM operations.
- K8S has the configuration of
priorityClassforPod, but it does not it does not have a way to dynamically consult thePodif it is good time to perform the LCM.
- K8S has the configuration of
- Does not have a way for applications to specify the preferred hardware and OS settings.
- Prefer big machines with more CPUs and memory in order to stack workloads and increase utilization.
- Cluster API has the concept of
MachineDeployment, but allMachinehas the same setting.
- Cluster API has the concept of
Twine architecture
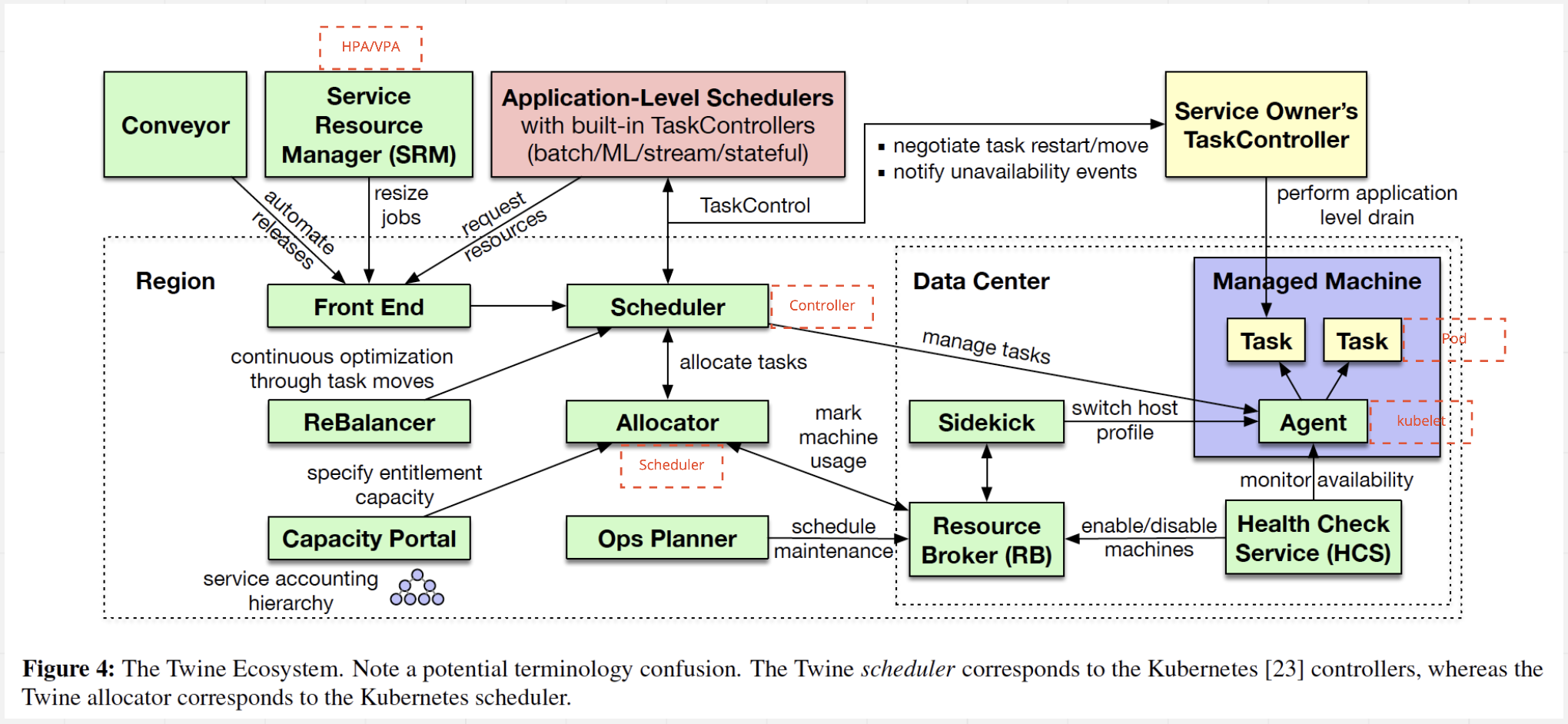
Task (Pod)
One instance of an application deployed in a container.
Job (Deployment)
A group of tasks of the same application.
Entitlement (Cluster)
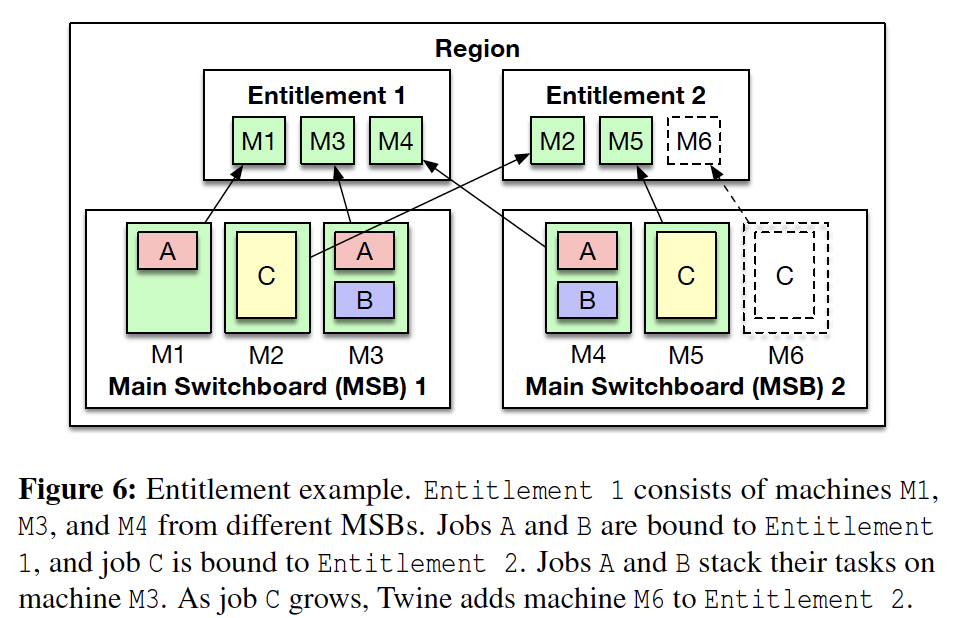
- An abstraction represents a group of machine to host jobs. It looks similar to the concept of cluster in K8S.
- Machines could be from different datacenters in a region.
- Twine binds job to an entitlement.
Agent (Kubelet)
Run on every machine to manage tasks. Like kubelet.
Scheduler (Controller manager)
- Cooperate with
Agent,Allocator,ResourceBrokerandTaskControllerto manage the lifecycle ofTaskandJobas the central orchestrator.
Allocator (Scheduler)
- Assign machine to entitlement.
- Assign tasks to machine.
- Talk to
ResourceBrokerto get machine information. - Use multiple threads for
Joballocation and optimistic concurrency control to handle the conflicts(Two threads try to handle the same job). And usetwo phase committo commit an allocation. - Use the in-memory
write-throughcache to speed up the repeatedJoballocation.
TaskController (K8S does not have)
- The API allows applications to collaborate with the cluster management system when deciding which operations to proceed and which to postpone.
- Handles three options:
- Move a
Taskfrom one machine to another. - Stop a
Taskand restart later. - Do nothing and keep the
Taskrunning.
- Move a
ReBalancer
- Asynchronously and continuously to improve the decision of
Allocator.
Resource Broker
- Store machine information.
- Handle machine unavailability events and notify
AllocatorandScheduler.
Health Check Service
- Monitor machines.
- Updates machine status in
Resource Broker.
Sidekick
- Apply host profiles to the machines as needed.
- All machines share the same host profile in one entitlement. It looks like
MachineDeploymentin K8S Cluster API makes all machines have the same flavor.
Service Resource Manager (HPA/VPA)
Auto-scale jobs in response to load changes.
How is a job deployed
- Front end handles a request which wants to deploy a
Job.- The request contains
entitlementID,allocationPolicyand other necessary inputs.
- The request contains
- Front end sends the request to
Scheduler. SchedulerconsultsAllocatoron where to deploy theTaskwithin aJob.- If no such
entitlementinstances exist:Allocatorgets theentitlementcapacity fromCapacity Portal.Allocatorassigns the freemachineto anentitlementby marking themachinestatus inResourceBroker.Sidekickwatches on the event of updatingmachinestatus then switch the host profile for that particularmachine.
Allocatorreturns themachineinformation(should be a list, because a Job has multiple Tasks) back toScheduler.
- If no such
Allocatornotifies theAgenton a particularmachineto start theTask(containerized application).
How is a task redeployed
Machine failure/maintenance or rolling update might make a task to be redeployed.
The redeployment is caused by machine unavailability
HealthCheckServicewill detect the unavailability and send an event toResourceBroker.ResourceBrokernotifiesSchedulerandAllocator.Schedulerdisables the affectedTask’s service discovery so that no clients could send requests to it.SchedulerconsultTaskControllerof thatJobto see if a move operation is allowed.TaskControllerresponses with the decision.- If yes:
Schedulerwill consultAllocatorto deallocate the affectedTaskfrom the unavailable machine by evict its cache entry.Schedulerwill consultAllocatorto allocate a new machine for the affectedTask.- The following steps are the same as the job deployment
- If no: Nothing to be done.
- If yes:
Schedulerre-enable the service discovery.
The redeployment is caused by rolling update
An example is to update the container image of a Job. A new task will be created, an old task will be terminated.
SchedulerconsultTaskControllerof thatJobto see if a stop operation is allowed.TaskControllerresponses with the decision.- If yes:
Schedulerwill disable the service discovery.Schedulerwill consultAllocatorto deallocate the affectedTaskfrom the unavailable machine by evict its cache entry.Schedulerwill instructAgentto stop theTask.Schedulerwill consultAllocatorto allocate a machine for the updatedTask.- The following steps are the same as the job deployment.
Schedulerwill re-enable the service discovery.
- If no: Nothing to be done. The current task will be up and running.
- If yes:
How does a machine get moved from one entitlement to another
Note:This is from my personal understanding
- A
machineneeds to be drained before the reassignment.SchedulerconsultsTaskControllerto get the acknowledgement. Otherwise, this will be a no-op.- [Optional]
SchedulerandAllocatorredeploy thetasks to different `machine. Schedulerstops the service discovery on allTasks from thatmachine.SchedulerinstructsAgentto stop all containers.SchedulernotifiesAllocatorthemachineis drained.AllocatorupdatesResourceBrokerby un-marking themachinefrom theentitlementand mark themachineto be available.
How does auto scaling work
Service Resource Manager is the components to use historical data of a service and predict the traffic, so that it could automatically send resize job request to front end in order to fulfill the horizontal auto scaling.
How does Twine control plane manage one million machines
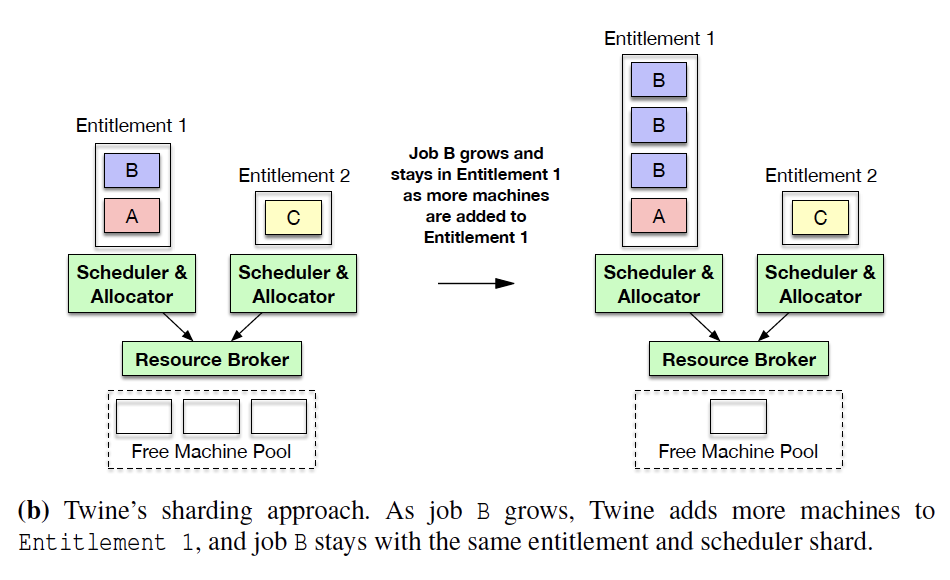
Shard the core components
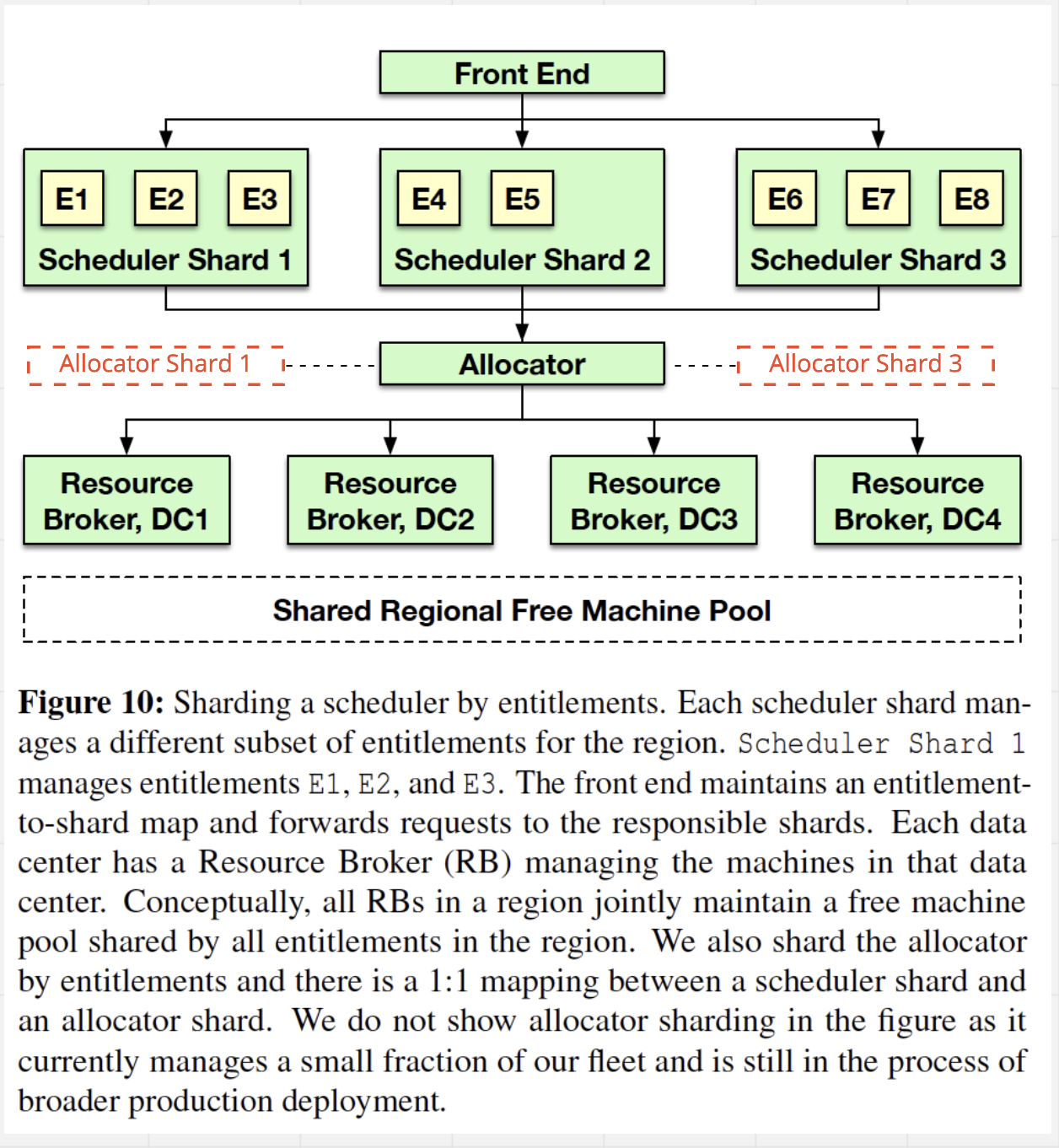
- Shard the
Schedulerto handle a subset ofentitlement. - Shard the
Allocatorto have 1:1 mapping toScheduler. - Each shard of
Allocatortalks to allResourceBrokers to allocate. - Each of above stateful component has its own separate external persistent store for metadata.
Application level scheduler to offload core scheduler
- Plugin model to support
Application-level schedulerwhich allocates and LCM tasks without involving Twine. (This sounds like the aggregated API server + custom controller in K8S)
FB Sharding VS K8S Federation
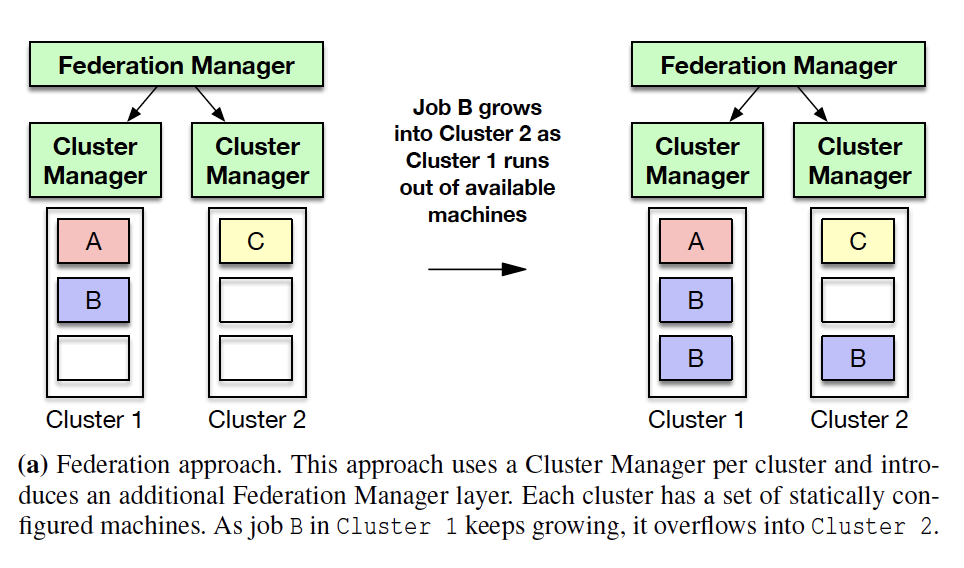
| Comparison | Twine | K8S |
|---|---|---|
| Machine allocation | Dynamic | Static |
| Job metadata management | Within same Scheduler and Allocator |
Split and distributed |
Availability
Single regional control plane could not handle the HA well. Twine has the following design principles:
- All components are sharded.
- All components are replicated(leader based).
- Decouple the application running from the lifecycle of Twine components, so that Twine components failure will not affect applications.
- Rate-limiting and circuit breaker(this is added by myself) to prevent destructive operations.
- Twine manages its own components as Twine job(except for
Agent). - Twine manages its dependencies as Twine job(E.g., ZooKeeper).