Design distributed message broker(RabbitMQ) and message streaming platform(Kafka)
Requirements
Functional requirements
- Multiple publishers produce messages
- Multiple consumers subscribe messages
Non-functional requirements
- Data persistent: Message cannot be lost before delivery
- Delivery guarantee: At least one
- Order guarantee: FIFO
- High available
- High scalability
- Efficient transfer and low IO latency
Assumptions
128 byte/message * 1000 messages/second/producer * 10000 producers = 1280 MB/second
- Need more than one node: With the growth of number of producers and messages producers send, we might not be able to hold all messages in the memory of a single node.
- All data could not fit in memory.
Data models and APIs
type Message struct {
ID string // the uuid of the message
Topic string // used for topic based message routing
Labels map[string]string // used for content based message routing
Content []byte // the message payload
}
func (Producer p) Publish(messageContent []byte, topic string, labels map[string]string) {
p.Send(Message{
ID: xxx,
Topic: topic,
Labels: labels,
Content: messageContent,
})
}
func (Consumer c) Consume(topic string, labels) []byte {
message := c.Consume(topic, labels)
}
Architecture
Kafka Architecture
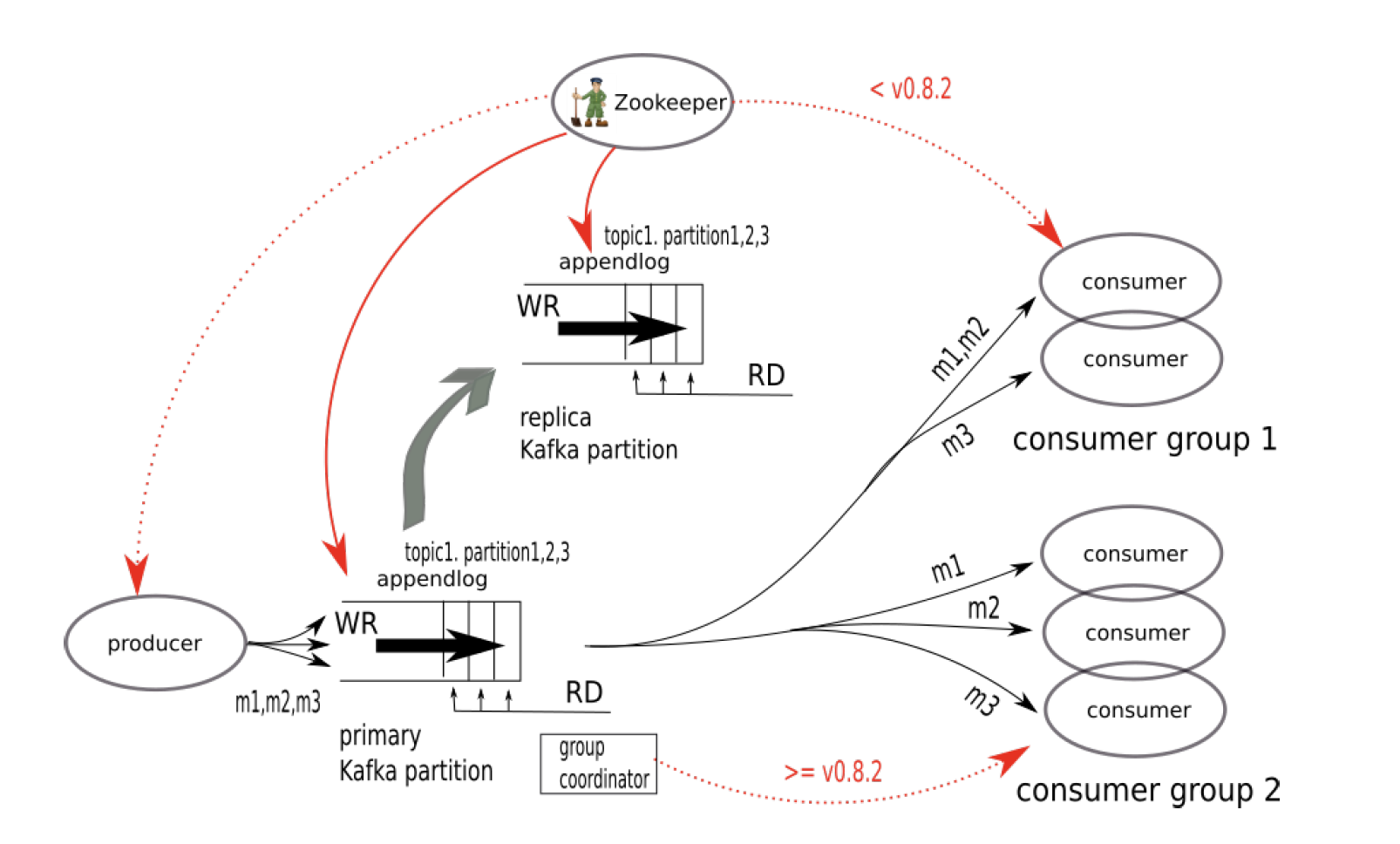
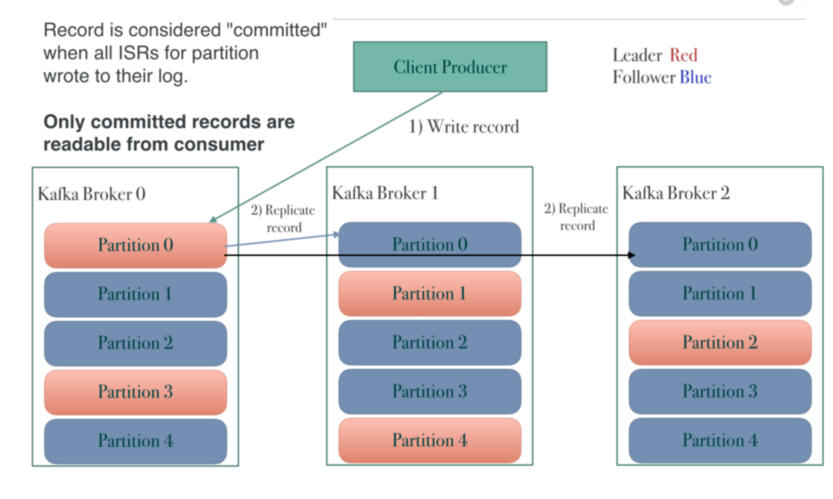
- Producer sends message to a topic.
- One topic has multiple partitions. A message is routed to one of the partitions(randomly or round-robin).
- Messages in a partition follows FIFO order(no ordering guarantee between partitions).
- Topics are managed by Zookeeper(service discovery, replica records).
- Messages are written to append-only log segments(use page cache to improve IO performance).
- Consumer consults ZooKeeper about the topic discovery.
- Consumer pulls message from a topic(based on offset).
- Consumer maintains the offset. Message ID has data length embedded, so it is easy to know how much data to load.
- ZooKeeper also records the last read offset in case of consumer failures.
How does Kafka know which consumers subscribe to a specific topic
-
Consumer Groups: Consumers don’t subscribe individually to topics. Instead, they join consumer groups, which act as logical units for message consumption. A consumer group can have multiple consumers working collaboratively to consume messages from the shared topics.
-
Group Coordinator: Each consumer group has a designated group coordinator, typically the leader of one of the partitions in the topic. This coordinator is responsible for managing group membership and keeping track of which consumers are subscribed to the topic within the group.
-
Group Metadata: Every consumer in a group maintains a local copy of the group metadata. This metadata includes information about all members of the group, including their IDs, leader status, and assigned partitions.
-
Heartbeats: Consumers periodically send heartbeats to the group coordinator. These heartbeats confirm their current status and presence in the group. If a consumer fails to send heartbeats within a specific timeout, the coordinator assumes it has left the group and removes it from the metadata.
-
Rebalancing: When a consumer joins or leaves a group, or a partition leader changes, the group coordinator initiates a rebalancing process. This process reassigns partitions among the active consumers in the group to ensure even load distribution and efficient message consumption.
-
Offset Commits: Each consumer tracks its progress within a topic by recording its offset, which indicates the last message it has processed. Consumers periodically commit their offsets to a dedicated topic called the consumer_offsets topic.
-
Offset Tracking: The group coordinator and all consumers maintain copies of the committed offsets for each consumer and partition. This allows the coordinator to track individual progress and reassign partitions during rebalancing based on current consumption positions.
In summary, Kafka uses a combination of consumer groups, group coordinators, metadata, heartbeats, rebalancing, and offset tracking to manage subscriptions and dynamically deliver messages to the appropriate consumers within each group. This system ensures efficient and resilient message flow while adapting to changes in group membership and partition leadership.
RabbitMQ Architecture
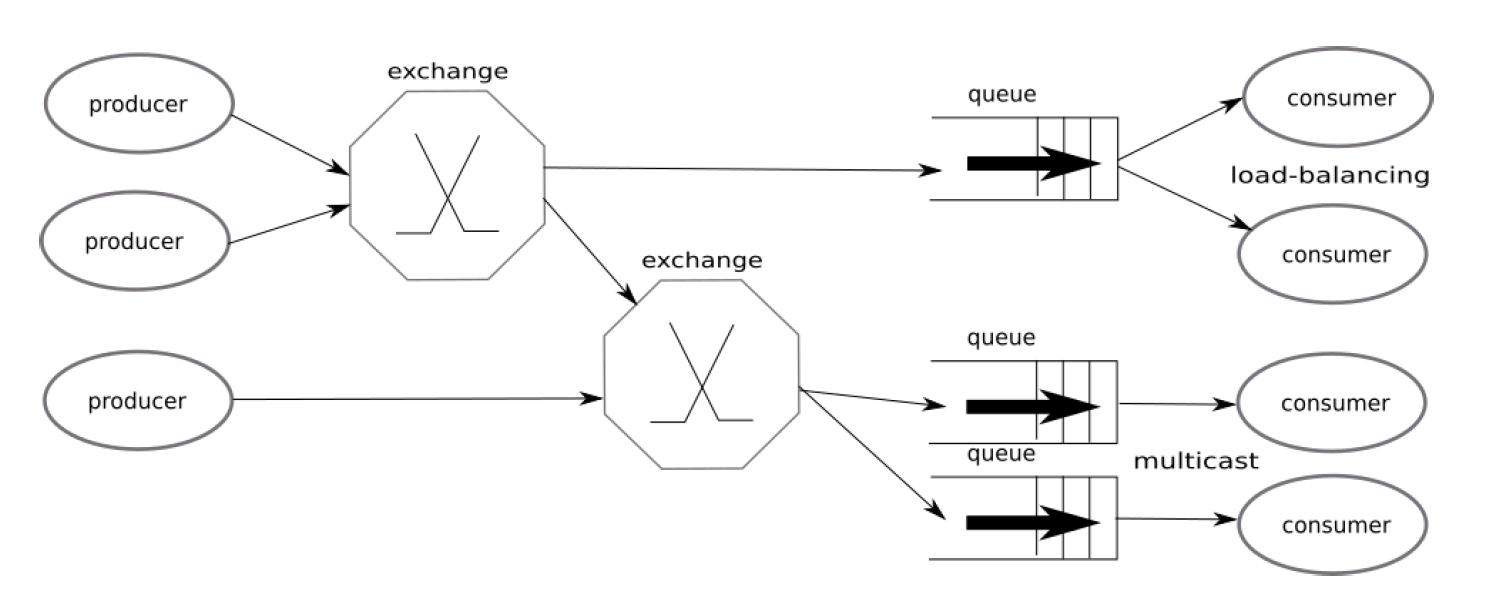
- Producer sends message to exchange.
- Exchange routes message to different downstream queues(topic based or content based).
- Messages are buffered in the downstream queue and will be pushed(by default or pulled from pull API) to consumers.
- Consumer registers itself to a specific queue and implements the handler for the delivery.
- Connections between RabbitMQ and consumers are established.
ConnectionFactory factory = new ConnectionFactory(); factory.setUri("amqp://userName:password@hostName:portNumber/virtualHost"); // provides a custom connection name Connection conn = factory.newConnection("app:audit component:event-consumer");
- Messages are stored in DRAM(has durability setting to configure how disk is involved).
- Messages are delivered to consumers in FIFO order from each queue(queue is sorted, so retry still keeps the order).
Data persistence
- RabbitMQ will store the messages in DRAM as long as possible, but once the available DRAM is completely consumed, RabbitMQ will start storing messages on disk without having a copy available in DRAM, which will severely impact performance.
- Kafka’s each partition is an ordered write-ahead log(using page cache to improve the performance) of messages that are persisted to disk.
Delivery guarantees
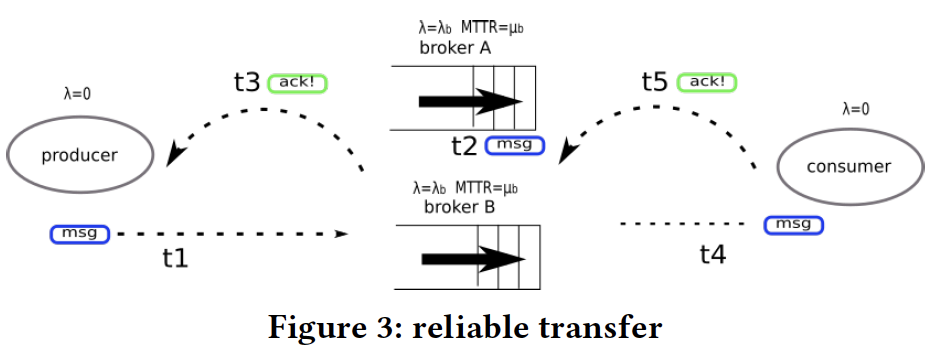
- t1: Producer sends message to queue.
- t2: Enqueue.
- t3: ACK returns to producer (ownership transfer from producer to queue).
- t4: Consumer gets message from queue.
- t5:
- RabbitMQ: Consumer sends ACK back to queue, so that it could delete the message.
- Kafka: Kafka does not maintain the message ownership information, so message will not be deleted from queue. Consumers could read from previous offset if failure happens.
How to guarantee at-least-once
- RabbitMQ: ACK from consumer.
- Custom implementation: Have a separate retry queue/hashtable to temporarily hold the consumed message(but not yet acknowledged).
- Kafka: Consumer could retry on previous offset.
How to guarantee at-most-once
- RabbitMQ: Discards the ACK from consumer, continue without waiting for ACK.
- Custom implementation: No separate retry queue/hashtable.
- Kafka: Consumer does not have to retry.
How to guarantee exactly-once
Two-phase commit:
--->Ask consumer “are you ready to consume”?.<---Consumer returns “yes”.--->Go ahead to consume.
Scalability
- RabbitMQ: Shard the queue into multiple queues and trade off the total ordering. https://github.com/rabbitmq/rabbitmq-server/blob/master/deps/rabbitmq_sharding/README.md
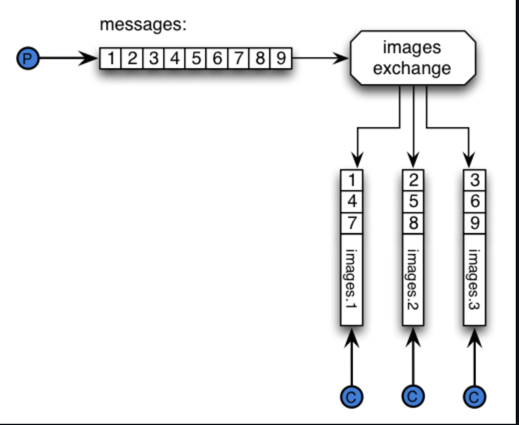
- Kafka: There are partitions within each topic.
Availability
- RabbitMQ: Leader based quorum queues implemented based on Raft.
- Kafka: ZooKeeper managed leader based topic replicas.
Fault tolerance
Producer failure
Producer fails before sending message
Producer could have its own retry logic.
Producer fails after sending the message but before getting the ack
Could have a separate store for message status, so that the producer could check the message status asynchronously. The broker could update the message status asynchronously as well(RabbitMQ could update when message is consumed/deleted from the queue; Kafka could update the message status in batch when ZooKeeper updates the last consumed offset.)
Producer fails after receiving the ack
No need to retry, just resume after the restart.
Middleware side failure
Host down or network partition
- If in the case of Kafka, the partitions on that host is not available. Leader election will promote another partition replica as the new leader and continue consuming the message.
- If in the case of RabbitMQ, the raft based quorum queue will have a new leader promoted to continue consuming messages.
In all above cases, both leader and follower could take the read/write requests. The only difference is the write request will be redirected to current leader. This is implemented by Raft algorithm already.
Process crashes
- If in the case of Kafka, it uses page-cache(read-ahead and write-back) to improve the disk IO. Most likely the data will still be in RAM, but the process loses the reference to the file descriptor. So no data lost in this case.
- If in the case of RabbitMQ, it uses the in-memory queue as the buffer to hold the message. If the process dies, the data within the queue is lost. If current queue is not leader, then it should be ok. If current queue is leader, then it is possible there is data lost(the uncommitted messages).
Consumer failure
Consumer crashes
- In the case of Kafka, it is ok since no data will be lost.
- In the case of RabbitMQ, the broker just stops sending data to the consumer if it is not responding.
References
- Kafka paper
- Kafka VS RabbitMQ paper
- https://www.youtube.com/watch?v=iJLL-KPqBpM&ab_channel=SystemDesignInterview
- https://medium.com/@vikashsahu4/kafka-a-distributed-messaging-system-for-log-processing-ce62e396626c
- https://betterprogramming.pub/rabbitmq-vs-kafka-1ef22a041793
- https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41
- https://tanzu.vmware.com/developer/blog/understanding-the-differences-between-rabbitmq-vs-kafka/
- http://cloudurable.com/blog/kafka-architecture-topics/index.html
- https://kafka.apache.org/documentation
- How Uber implements at-least-once